Marco Cagrandi, Marcella Cornia, Matteo Stefanini, Lorenzo Baraldi, Rita Cucchiara
Proceedings of the ACM International Conference on Multimedia Retrieval (ICMR 2021)
June 2021
Abstract
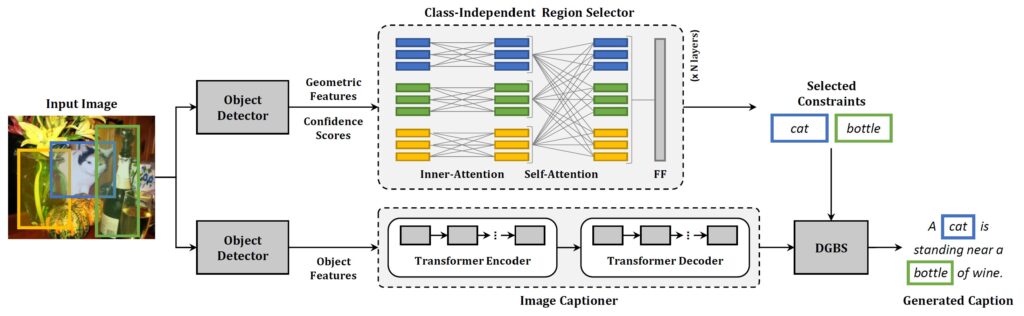
Image captioning models have lately shown impressive results when applied to standard datasets. Switching to real-life scenarios, however, constitutes a challenge due to the larger variety of visual concepts which are not covered in existing training sets. For this reason, novel object captioning (NOC) has recently emerged as a paradigm to test captioning models on objects which are unseen during the training phase. In this paper, we present a novel approach for NOC that learns to select the most relevant objects ofan image, regardless of their adherence to the training set, and to constrain the generative process of a language model accordingly. Our architecture is fully-attentive and end-to-end trainable, also when incorporating constraints. We perform experiments on the held-outCOCO dataset, where we demonstrate improvements over the state of the art, both in terms of adaptability to novel objects and caption quality.
Type: Conference Paper
Publication: ACM International Conference on Multimedia Retrieval (ICMR 2021)
Full Paper: link pdf
Please cite with the following BibTeX:
@article{cagrandi2021learning,
title={Learning to Select: A Fully Attentive Approach for Novel Object Captioning},
author={Cagrandi, Marco and Cornia, Marcella and Stefanini, Matteo and Baraldi, Lorenzo and Cucchiara, Rita},
journal={arXiv preprint arXiv:2106.01424},
year={2021}
}