Manuele Barraco, Matteo Stefanini, Marcella Cornia, Silvia Cascianelli, Lorenzo Baraldi, Rita Cucchiara
Proceedings of the International Conference on Pattern Recognition (ICPR 2022)
April 2022
Abstract
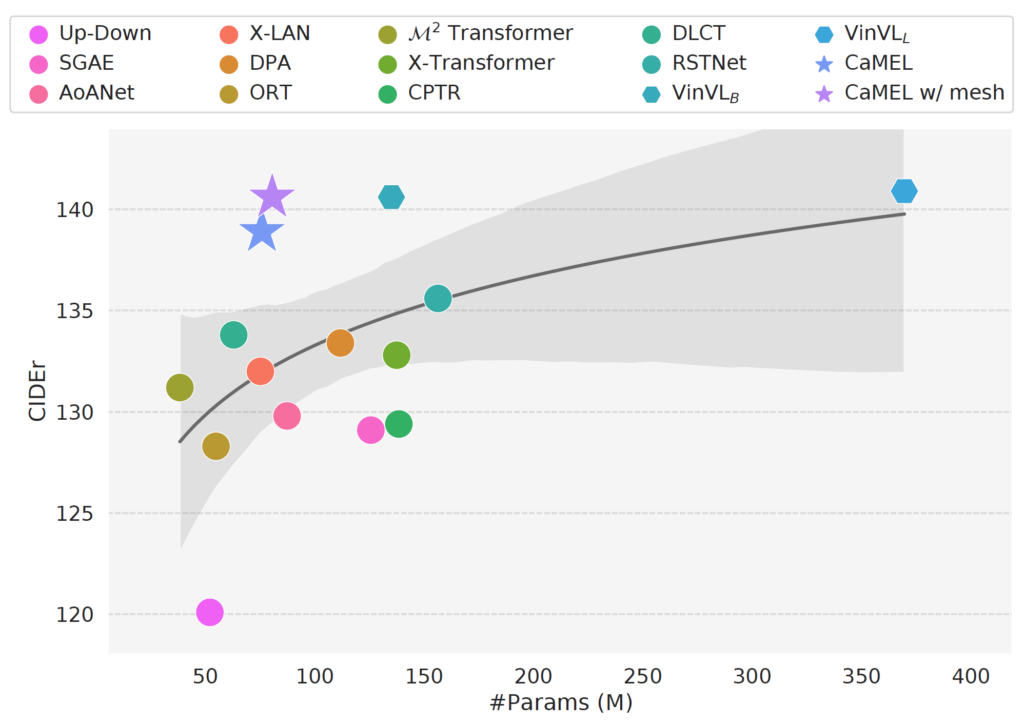
Describing images in natural language is a fundamental step towards the automatic modeling of connections between the visual and textual modalities. In this paper we present CaMEL, a novel Transformer-based architecture for image captioning. Our proposed approach leverages the interaction of two interconnected language models that learn from each other during the training phase. The interplay between the two language models follows a mean teacher learning paradigm with knowledge distillation. Experimentally, we assess the effectiveness of the proposed solution on the COCO dataset and in conjunction with different visual feature extractors. When comparing with existing proposals, we demonstrate that our model provides state-of-the-art caption quality with a significantly reduced number of parameters. According to the CIDEr metric, we obtain a new state of the art on COCO when training without using external data. The source code and trained models are publicly available.
Type: Conference Paper
Publication: International Conference on Pattern Recognition (ICPR 2022)
Full Paper: link pdf
Code: link github
Please cite with the following BibTeX:
@inproceedings{manuele2022camel,
title={CaMEL: Mean Teacher Learning for Image Captioning},
author={Manuele, Barraco and Stefanini, Matteo and Cornia, Marcella and Cascianelli, Silvia and Baraldi, Lorenzo and Cucchiara, Rita},
booktitle={International Conference on Pattern Recognition},
year={2022}
}