Marcella Cornia, Matteo Stefanini, Lorenzo Baraldi, Massimiliano Corsini, Rita Cucchiara
Pattern Recognition Letters
September 2019
Abstract
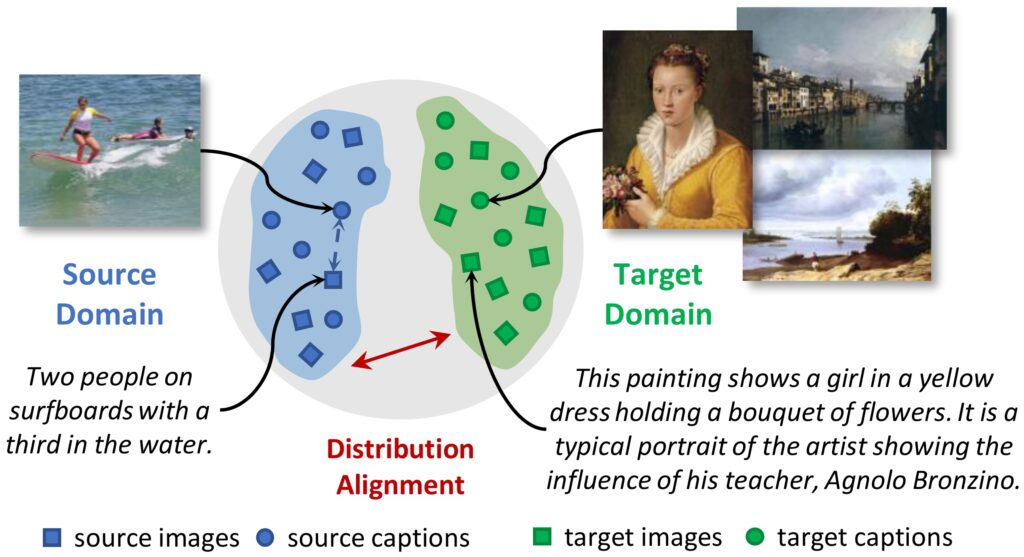
Replicating the human ability to connect Vision and Language has recently been gaining a lot of attention in the Computer Vision and the Natural Language Processing communities. This research effort has resulted in algorithms that can retrieve images from textual descriptions and vice versa, when realistic images and sentences with simple semantics are employed and when paired training data is provided. In this paper, we go beyond these limitations and tackle the design of visual-semantic algorithms in the domain of the Digital Humanities. This setting not only advertises more complex visual and semantic structures but also features a significant lack of training data which makes the use of fully-supervised approaches infeasible. With this aim, we propose a joint visual-semantic embedding that can automatically align illustrations and textual elements without paired supervision. This is achieved by transferring the knowledge learned on ordinary visual-semantic datasets to the artistic domain. Experiments, performed on two datasets specifically designed for this domain, validate the proposed strategies and quantify the domain shift between natural images and artworks.
Type: Journal Paper
Publication: Pattern Recognition Letters
Full Paper: link pdf
Please cite with the following BibTeX:
@article{cornia2020explaining,
title={Explaining digital humanities by aligning images and textual descriptions},
author={Cornia, Marcella and Stefanini, Matteo and Baraldi, Lorenzo and Corsini, Massimiliano and Cucchiara, Rita},
journal={Pattern Recognition Letters},
volume={129},
pages={166--172},
year={2020},
publisher={Elsevier}
}